
A big focus for 2024: Improving genre & topic accuracy (and expanding that system).
It is a trickier problem then you think...

Every two weeks, I share my notes on building Shepherd.com.
I believe that books build better people. I am on a mission to help readers explore & discover books in new and unique ways. I want to create the magical feeling you get wandering around your favorite bookstore but for the online world. And I want to do this while helping authors to expose their stories, personalities, and books.
Three hurrahs for our 588 Founding Members who keep us independent and fund new features. My 2024 goal is to reach 1,000 members to fully fund our part-time developer and designer so we can keep building great new features for our community.
January 15th to January 26th
Mood check 🤪

Funny walks are the best walks.
How does the genre and topic system work right now?
Topic System
First, we pull in data about the book using two systems.
If a book is in the Library of Congress, we bring in their topics.
We feed data we have about the book to an NLP/ML project called Wikifier, and it tells us what Wikipedia topics the book is connected to. This works better for nonfiction since that is easier to determine using AI.
Then, we rank those topics by the strength of connection. Library of Congress data is given a “most accurate” status, and then Wikifier's picks come in below that.
The top 5 topics for that book are used in various ways on Shepherd.
Here is a screenshot to show this section for the book The Sword and the Shield: The Revolutionary Lives of Malcolm X and Martin Luther King Jr.

I had to manually do some edits on this one because AI gets confused between Martin Luther and Martin Luther King Jr.
This system is not perfect. I’d give a grade of a B- on most nonfiction and a C- on fiction. Fiction is more problematic as it is often more theme than topic.
And there is a lot of manual work here:
I’ve manually banned 35,000+ topics that AI picked up but that I don’t think are helpful for book discovery. These are things like the names of books, concepts like “Regent,” sports names, and so many other random things.
I’ve manually reviewed 8,000+ topics that I think are a good fit.
That is a decent summary of how the topic system currently works. In a second, I’ll talk about the problems and improvements…
Genre System
First, we pull in data about the book’s genres from our book API provider (Nielsen). This uses a system called BISAC, a genre system used in the USA. You can browse their list of genres here.
Here is what this looks like for the book Dune.
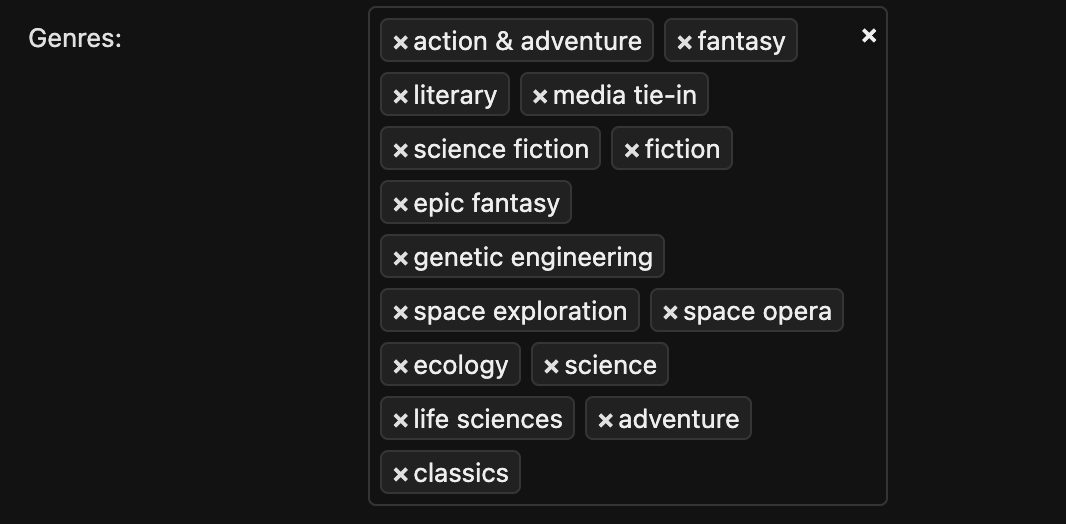
We try to pull in all the different editions of Dune and all their genre tags.
This can get messy as you see above that a publisher tagged Dune with “science,” which means the publisher didn’t understand the BISAC system and tagged Dune as “nonfiction.”
And as you can probably see, BISAC is very limiting. It does not reflect how most readers view genres and has some big limitations. Many publishers tag all fantasy books as also being science fiction (and vice versa). They also abuse genres like “hard science fiction,” which is frustrating.
That is a decent summary of how the genre system currently works. In a second, I’ll talk about the problems and improvements…
How do these genres and topics get used to create bookshelves?
Each bookshelf is a little recipe for how to pick the books within it.
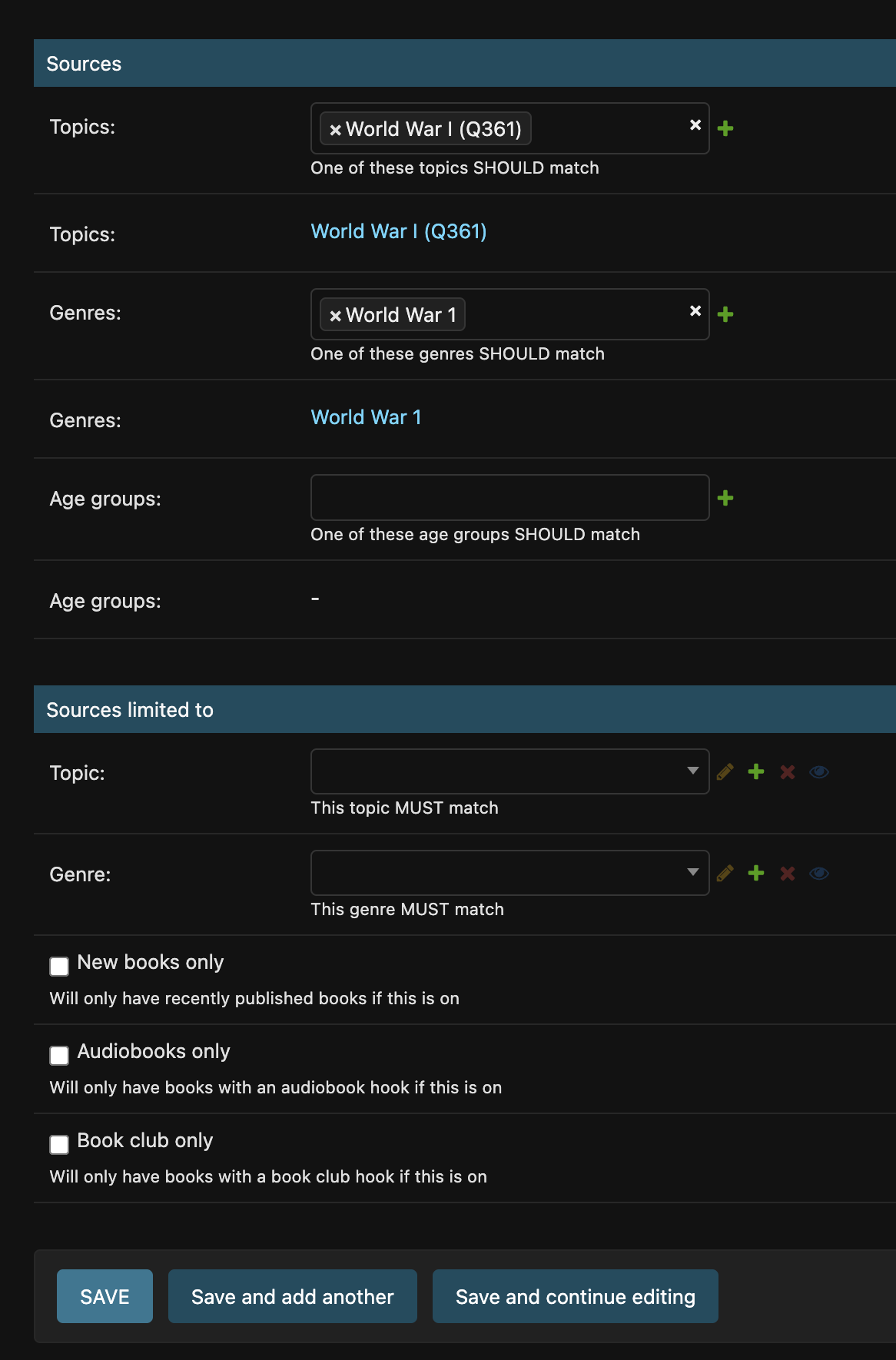
Here, we tell it to make a bookshelf out of all the books with topic WW1 or genre WW1. Because right now, those are separate systems.
Here is the result, our WW1 bookshelf: https://shepherd.com/bookshelf/world-war-1
Here is another example of trying to build a bookshelf for “spy thrillers.”

In this case, we take all the books with the topic “spy” or the genre “espionage,” and then we cut any book that doesn’t also have the genre “thriller.”
Here is the result: https://shepherd.com/bookshelf/spy-thriller
In some cases, this is quite straightforward, such as when there is a genre in BISAC for “military science fiction,” then we don’t need to do anything fancy.
Hopefully, that helps you understand the recipe builder for putting these together.
What are the problems with the genre and topic system?
Genre System
The BISAC genre system has a lot of “genres” that are actually topics. So, we end up having a genre for WW2 and also a topic for WW2.
With the BISAC genre system we get a lot of mess from publishers. If they choose a nonfiction and fiction categories, our system marks the book as fiction and nonfiction. And some publishers abuse the system or push inaccuracies for gain.
The BISAC system lacks a lot of popular genres that readers search for. We have the ability to create custom genres, but we have to have some way to know which books belong in that category.
Sometimes, genres like romance don’t seem accurate to what readers expect. I need to test more here, but I am unsure if there is a big difference between what the publishing industry calls romance and what readers call romance.
Topic System
The accuracy of the AI system could be improved for fiction and nonfiction. And with fiction, I might lean toward theme rather than topic. The system has a tendency when it struggles to identify topics to assign books to World War 2 (which is kinda funny).
I need to refine and evolve how readers want to connect with books. When readers search for “Japan,” we scoop off all books with that topic as one of their 5 topics. So this can be thrillers set in Japan, travel books about Japan, and books on Zen Buddhism that mention Japan. The strength of that connection to Japan is hard to judge, and I need to look at what we should do here. A big goal of mine is serendipity, as I want to make sure readers get the unexpected but still with strings to what is on their mind. That is hard to accomplish, and I need to play with it.
How are you going to fix these problems?
I am not sure.
I will be doing a lot of research and testing over the first half of 2024.
Because this system is so complex, having the developer work on it is expensive. So, I want to do a lot of research before we start revamping it to improve the quality.
What are the things I will be looking at?
Can ChatGPT or other AI systems improve the topic system? Can they help determine the genre when there is chaos from the publishers? Early results look promising.
I need to look at the way we map data sources to genres and topics. I am unsure if the system is working the way it should and might be needlessly complex. Can I streamline it while making it more accurate? Can I make it easier to add new sources? Does it need to be improved, or is it good enough for now?
I will be working to expand the system to add more topics/genres to our search engine and as bookshelves.
What else am I working on?
I am training a new part-time editor this week and next. Serita, our long-time part-time editor, is leaving Shepherd as one of her projects has picked up in scope. I am very sad to see her go :(.
I am cleaning up a lot of internal processes and improving how they work
What is going on outside of Shepherd?
For the last few weeks, my wife has been in the USA helping her mom recover from surgery. So, I have been entirely in charge of my son’s daily routine. It has been busy but also a lot of fun 😀.
What am I reading?
M: Son of the Century - About Mussolini. I'm stalled, but I'm hoping to pick it up soon.
Wounded Tigris: A River Journey Through the Cradle of Civilization by Leon McCarron.
Thanks, Ben
P.S. From a recent adventure weekend with my son!
